My friends and colleagues, Stephen Ansolabehere and Eitan Hersh, have just published an article with the journal Statistics and Public Policy with the sexy title, “ADGN: An Algorithm for Record Linkage Using Address, Date of Birth, Gender, and Name.” I highly recommend it. Here are a couple of thoughts about the paper and why it’s important.
The paper does two major things. First, it provides an easily implementable matching algorithm for people doing work in this field. Second, it provides important guidance about how states might think about protecting personally identifying information while at the same time making voter lists public. Data geeks will be interested in the first thing; everyone should be interested in the second thing, especially as the community struggles with the privacy implications of the voter registration list requests made by the Presidential Advisory Commission on Election Integrity, also known as the Pence-Kobach Commission.
Background
First, the article’s background. The article arose from expert work Ansolabehere and Hersh did working as social scientists the Department of Justice in two Texas voter ID cases that arose under the Voting Rights Act, Texas v. Holder and Veasey v. Abbott. Denizens of election administration and election science recognize the importance of these cases for the ongoing controversy about the implementation of strict photo voter ID laws.
What may be less appreciated is that the empirical work that Ansolabehere and Hersh had to conduct confronted (at least) three challenges: (1) the Texas voter registration file does not contain the race of the voter, (2) the databases to be matched did not contain the full nine-digit Social Security Number (SSN9), which is the gold standard of matching criteria, and (3) the Texas voter file and the associated ID files (driver’s licenses, passports, and many others) are enormous. The first challenge had to be surmounted so that they could draw conclusions about any racially disparate impacts of the ID laws. The second and third challenges had to be surmounted if the question about the racial impact of the voter ID law was to be addressed empirically.
Leaving aside the first challenge, matching databases in a setting like this is tough because of the sizes of the data sets in question. Many record linkage algorithms have been developed in the context of relatively small data sets — or at least one small data set being matched against one large one. Because of the necessity to minimize both false positive and false negative matches — for good substantive and strategic reasons — and the need to meet tight litigation schedules, the standard linkage algorithms that academics have developed and applied in other settings aren’t easily used in Voting Rights Act cases.
On top of all this, from the perspective of getting high-quality matches between voter registration and ID data bases, let’s just say the data can be a bit messy. Typos, name changes, inconsistent data-entry standards, etc. plague the data set matching effort.
The ADGN algorithm
The solution Ansolabehere and Hersh offer to the matching problem is to build matching terms based on combinations of the house numbers and ZIP Code from the Address, Date of Birth, Gender, and Name. In the best of circumstances, if we have perfect data in both data sets to be matched, then the combination of all four elements (ADGN) almost perfectly uniquely identifies someone in the two data sets being matched. Perhaps even better, when the data aren’t perfect, most of the triples of these elements create matching keys that are almost just as good, such as ADN (excluding gender) or ADG (excluding name).
The following graph (Figure 1 in their article) shows the degree to which different combinations of the ADGN elements create unique identifiers in the Texas voter file.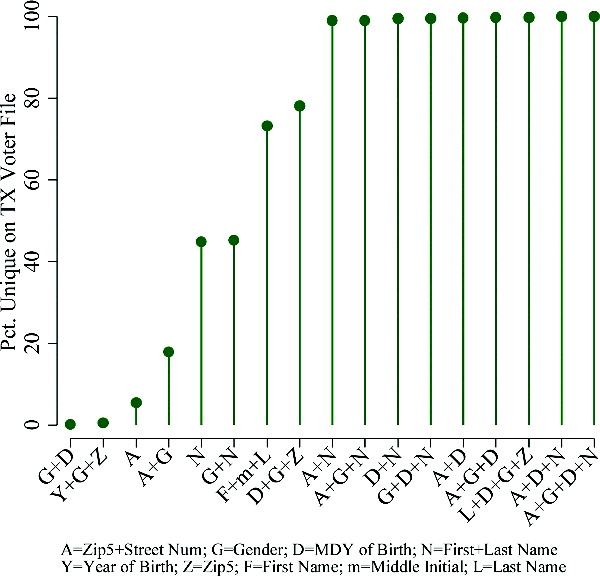
Ansolabehere and Hersh are able to take advantage of the fact that a subset of the Texas voter file did have the full SSN9. Thus, they were able to compare matches that used SSN9 to merge the voter file with the driver’s license file with matches that used the ADGN algorithm. As they state in the abstract to the article, they show “that exact matches using combinations A, D, G, and N produce a rate of matches comparable to 9-Digit Social Security Number.”
The policy contribution
Eitan Hersh, the author of the very fine book on voter registration lists, Hacking the Electorate, has become a leading light thinking through the ethical implications of making voter lists available to the public in the age of big data. Thus, it’s not surprising that an article like this also has some very smart thoughts about the policy of releasing voter lists to the public. Releasing voter lists to the public is a necessary part of maintaining the integrity of the voting process, conducting campaigns, and doing research into the electoral process. However, the full lists — the ones maintained by election officials for the conduct of elections — contain personally identifiable information that no one wants disseminated widely. How do we balance the need to disseminate voter lists with the need to protect voters against identity theft?
Ansolabehere and Hersh conduct detailed analysis of the degree to which the data elements in a typical voter list help to identify individuals. They show that if you have the full name, gender, date-of-birth, and address of a voter, you pretty much can identity that individual perfectly in any other data set you might match against. However, if you mask name and then only report birth year, it becomes very hard to identify individuals in a voter file — the combination of birth year, gender, the ZIP5 only uniquely identifies 0.42% of individuals in the Texas voter file, for instance.
Of course, the parties — along with academics who use the files as sampling sources — would squeal if states removed the names from the voter files made available to them. However, a voter file without names and only ZIP5 (plus, perhaps precinct) for address would be all that most election science researchers and voter integrity activists need to do their work. Certainly, as states re-think their policies about the public release of voter registration lists, using the Ansolabehere-Hersh paper to think about wise data redaction policies is a better route to take, rather than just simply refusing to release any form of voter files altogether.